Everything Everywhere All at Once#
Infinite Possibilities: AI’s Journey Towards Understanding Everything, Everywhere, All at Once











































































































Prologue: Setting the Stage#
1. Emergence of a New Era#
Welcome to a journey through time and space, where Artificial Intelligence (AI) is not just a concept, but a transformative force echoing the sentiments of the film “Everything Everywhere All at Once”. The vast, ever-expanding world of AI is reshaping our understanding of intelligence, language, and reality itself.
Our tale will traverse through the landscapes of large language models, attention mechanisms, reinforcement learning, and autonomous agents. We’ll explore the paradoxes of hallucinations in AI, the intricate web of knowledge graphs, and how AI models strive to understand the world. We’ll also delve into the cutting-edge tools and techniques shaping AI’s future, such as LangChain, Llama Index, Segment Anything Model (SAM), DINOv2, and ImageBind.
Just as the film “Everything Everywhere All at Once” encapsulates the complexity and interconnectivity of existence, so too does our exploration of AI. It’s a journey towards understanding everything, everywhere, all at once. Buckle up, and let’s dive into the emergence of this new era.
2. Deciphering Intelligence: Memory vs Understanding (Intelligence)#
What, we ask, is the true essence of intelligence? Is it our ability to recall vast amounts of information or the capacity to comprehend and interpret the world around us?
Take IBM’s Watson, for instance, a powerful AI system that made headlines for its spectacular victory in the game show Jeopardy! in 2011. Watson, powered by the Deep QA software, was designed to analyze natural language input and sift through a vast amount of information to deliver precise, relevant answers. However, despite its impressive processing capabilities and speed, Watson operates more like a fast-processing machine than a truly intelligent entity.
While Watson can store and recall a gargantuan amount of data with remarkable accuracy, it essentially mirrors human intelligence, reflecting back the information it has been fed. The real challenge lies in moving beyond this echo, in creating AI systems that can not only remember but also truly understand the world in the same way humans do.
This intriguing conundrum brings us to the exciting frontier of AI research—the development of world models. Can we design AI systems that go beyond memory, that can interpret, make sense of data, see patterns and connections, and make informed decisions based on this understanding? This is the riddle that we will unravel as we venture deeper into the fascinating world of AI, exploring its strengths, limitations, and immense potential. Let’s dive in.
3. Decoding the Language of the Universe: Language Understanding and the Necessity of World Models#
In this next act, we embark on a journey into the intricate world of language and its understanding. Language, in all its diverse forms, is the code through which we decipher the universe. It’s a universal phenomenon, a shared method of communication that transcends cultural and geographical boundaries.
Artificial intelligence has made significant strides in decoding this complex system of communication. Large Language Models (LLMs) like GPT-4 are capable of generating impressively coherent and contextually relevant responses. They’ve begun to master the art of language imitation, replicating human-like text based on the data they’ve been trained on.
But is imitation the same as understanding? This is a question that pushes the boundaries of what we currently know about artificial intelligence. To truly understand language, an AI must grasp not just the semantics of words and sentences, but also their underlying meaning in a given context. It needs to have a conception of the world, a world model, that informs its understanding and use of language.
Imagine a conversation about a beach vacation. To fully understand and engage in such a conversation, one must know what a beach is, what constitutes a vacation, the common activities associated with a beach vacation, and so on. This information isn’t encapsulated in the words themselves, but in our shared understanding of the world.
Previous AI systems, like IBM’s Watson, excel at information retrieval and question answering based on their training data. However, they lack an internal world model—an understandable model of the process producing the sequences. Without this, their understanding of language is limited and surface-level, dependent on the specific inputs they’ve seen during training.
The challenge, and the next frontier in AI research, is to build AI systems that do more than just mimic human language. The goal is to create systems that develop an internal model of the world, allowing them to truly understand and generate language in the way humans do.
Act 1: Back to the Origins#
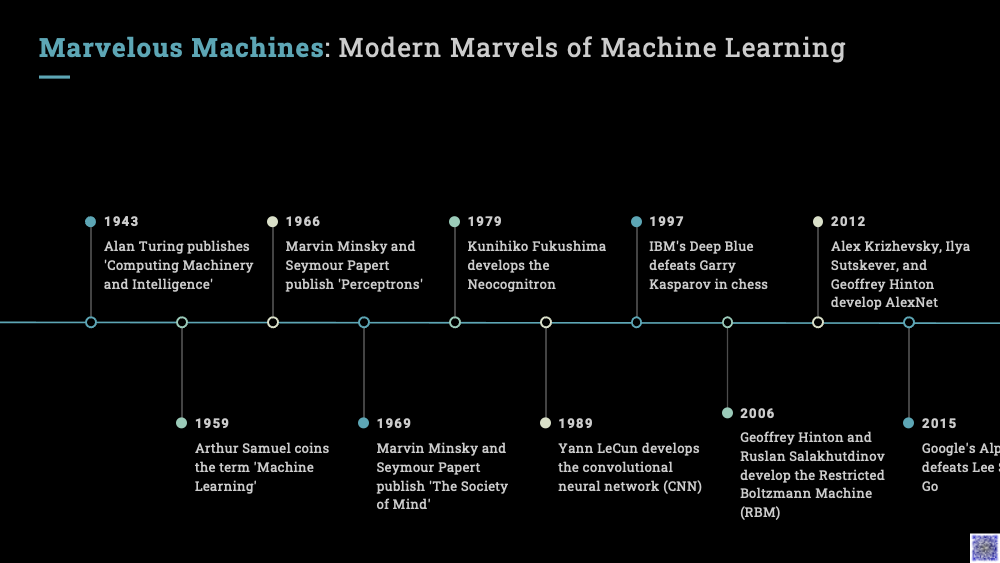
4. Turing’s Echo: Imitation Game, Alan Turing, and his influence on attention mechanisms in AI#
Now, we will be travelling back in time to the era of Alan Turing, the father of theoretical computer science and artificial intelligence. Turing was a visionary who foresaw the potential of machines to not just calculate, but also to mimic human intelligence.
Turing proposed a simple, yet powerful test to measure a machine’s ability to exhibit intelligent behavior equivalent to, or indistinguishable from, that of a human. This test, now known as the Turing Test or the Imitation Game, is based on a machine’s ability to carry on a conversation that is indistinguishable from a conversation with a human being. The core of the Turing Test is imitation, the ability to generate responses that mirror those a human would give. This principle has greatly influenced the development of AI.
Turing, a pioneer in theoretical computer science and AI, introduced the concept of a ‘universal machine’ that could simulate the logic of any computer algorithm, irrespective of its complexity. This idea, the Turing Machine, became a fundamental concept in computer science, shaping our understanding of computational processes.
The Turing Machine operates using an infinitely long tape filled with symbols and a head that interacts with this tape. Although this model’s infinite memory renders it a theoretical model rather than a practical computing machine, it serves as a crucial foundation in understanding computation’s nature.
Building upon Turing’s groundbreaking concept, the Neural Turing Machine (NTM) emerged, coupling a neural network with external memory storage. The NTM, similar to Turing’s model, consists of a tape-like memory bank and a controller network functioning as the operating head. However, in contrast to the original Turing Machine, the NTM uses finite memory, resembling a “Neural von Neumann Machine”.
The NTM’s controller, a flexible neural network, can be either feed-forward or recurrent, interacting with the memory bank to process input and generate output. This interaction is managed by a set of parallel read and write heads, softly attending to all memory addresses in a “blurry” manner, reminiscent of human attention mechanisms.
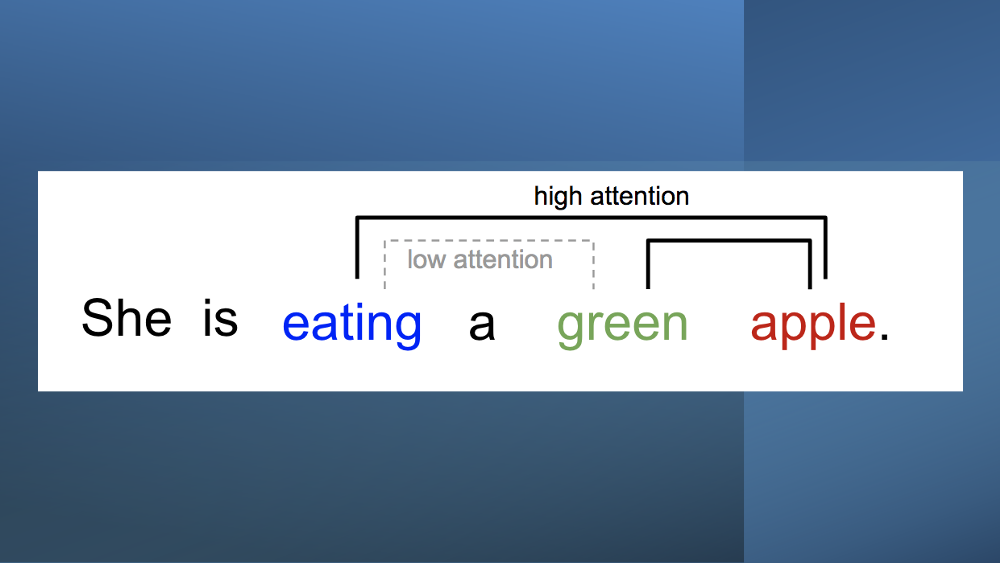
Indeed, this concept of “attention” is a cornerstone in modern AI, heavily inspired by human cognitive processes. Just as we focus our attention on different regions of an image or various words in a sentence, AI’s attention mechanisms determine the importance of different pieces of information when performing a task.
For instance, when viewing a picture of a Shiba Inu, our attention may first focus on the dog’s pointy ears, then shift to its attire, and finally its surroundings. This dynamic focusing of attention allows us to understand the image as a whole while still recognizing its individual elements. Similarly, in a sentence, the word “eating” might lead us to anticipate a word related to food.
In the context of AI, an attention mechanism follows a similar pattern, assigning different weights of importance to various elements of an input. By correlating these elements based on their assigned weights, the AI can generate an accurate approximation of the desired output. The influence of Alan Turing’s work is echoed in the development of attention mechanisms in AI, showcasing the enduring impact of his visionary ideas.
5. The Library of Babel: Attention Mechanism Explained Through the Library Analogy#
Imagine entering an enormous library, an endless maze of books akin to Borges’ “Library of Babel”. Your task is not just to read every book, but to comprehend and make sense of the vast knowledge contained within. This is analogous to the task of an AI model processing large volumes of data. Merely “reading” or processing the data does not guarantee understanding. The AI model, just like a person in the library, must formulate questions (Q), seek out answers (V), and use clues (K) to comprehend the data.
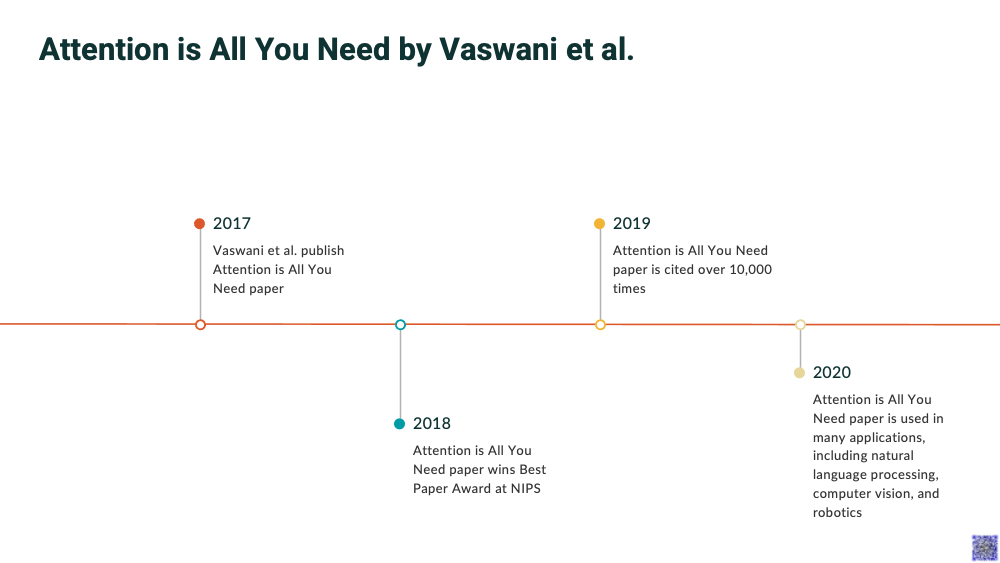
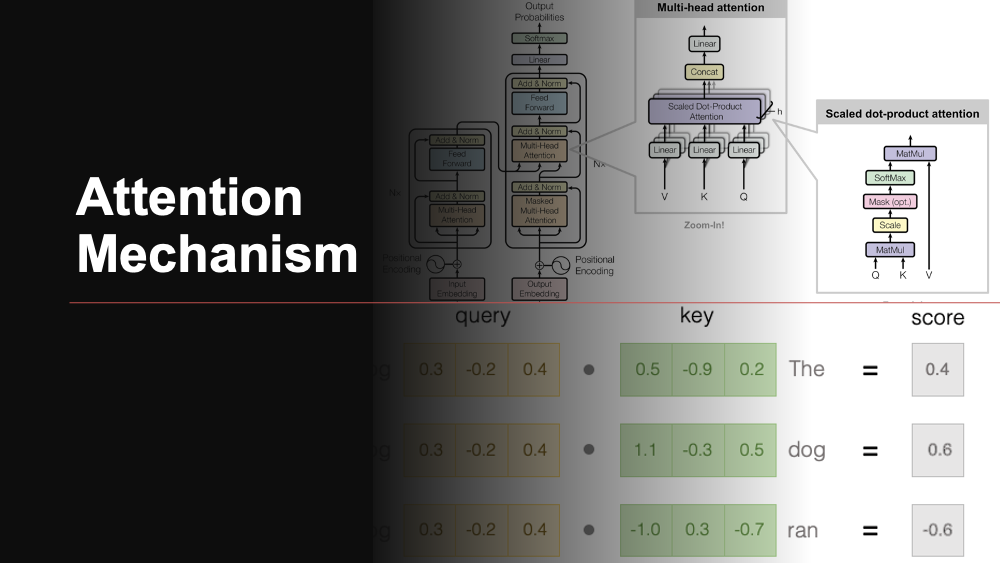
This process is akin to the “Attention Mechanism” in AI, specifically highlighted in the 2017 paper “Attention is All You Need” by Vaswani and colleagues. The paper introduced the “transformer” model, built entirely on self-attention mechanisms, bypassing the need for sequence-aligned recurrent architecture.
The transformer model uses an innovative approach, viewing the encoded representation of the input as a set of key-value pairs. Imagine each book in the library as a key-value pair, where the key is the book’s subject or title, and the value is the information within. The model then formulates a query, analogous to a question you may ask yourself in the library. The query is mapped to the set of keys and values (the books), leading to an answer.
The transformer uses the “scaled dot-product attention” mechanism, which is like weighing the relevance of each book in the library to your question. The more relevant a book, the higher its weight. The final answer is a sum of the values (information) weighted according to their relevance.
The transformer goes a step further with “multi-head self-attention”, akin to having multiple versions of yourself simultaneously exploring different sections of the library. Each “head” independently calculates attention, with their outputs concatenated and transformed into the final output. This mechanism allows the model to attend to information from different representation subspaces at different positions.
To return to our library analogy, imagine each head focuses on a different genre or topic, helping you understand the library’s content from multiple angles simultaneously. This multi-faceted approach enables the model to better understand and interpret the input data, reflecting the rich complexity of human attention and comprehension processes.
Act 2: The Learning Curve#
6. Pioneering with Caution: Reinforcement Learning from Human Feedback (RLHF)#
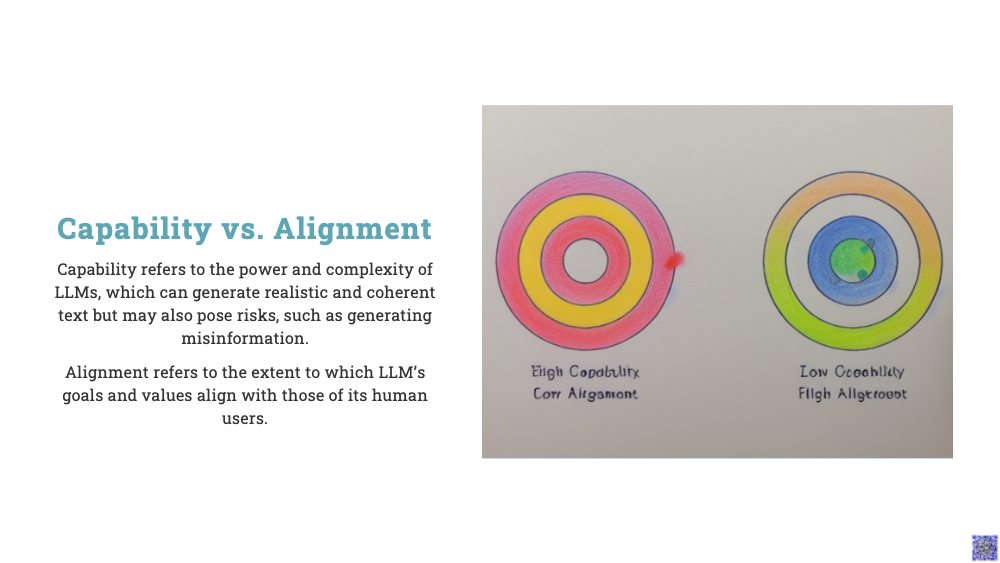
As we stand on the precipice of a new era in AI, we’re challenged with not just the potential, but also the responsibility that comes with it. Generative AI, a technology that has spurred a race of innovation, holds the potential to revolutionize multiple sectors of our society. However, it’s crucial that we navigate this path with caution, aware of the associated risks, ensuring that AI aligns with our values and contributes positively to our society.
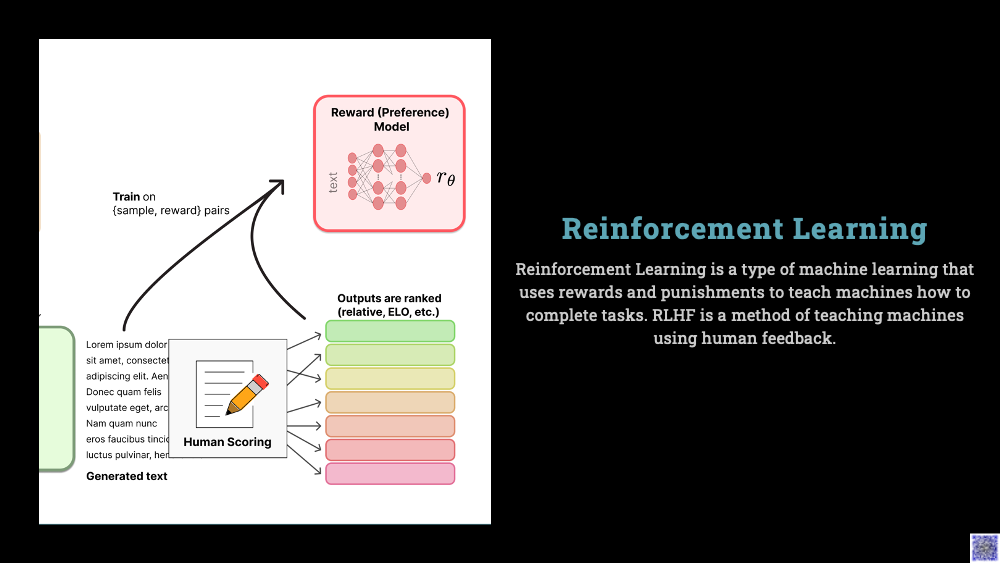
Reinforcement Learning from Human Feedback (RLHF) has emerged as a significant paradigm in this context, striving to make AI helpful, honest, and harmless by aligning it with human values. This innovative approach combines the power of reinforcement learning with the nuance and context-awareness of human feedback. Reinforcement learning is an AI technique where an agent learns to make optimal decisions through a system of rewards and penalties, akin to a child learning from his mistakes.
However, the challenge lies in defining a reward function that can capture the full spectrum of human values and preferences, a task that can be dauntingly complex. RLHF addresses this issue by incorporating human feedback into the training process. This human-AI feedback loop enables the model to learn more efficiently and align more closely with human values. It allows humans to correct and provide guidance when the model provides inappropriate or harmful responses, ensuring the AI’s decisions are responsible and beneficial.
Imagine an AI-powered robot designed to cook pizzas. An automated reward system can measure and optimize for objective factors like crust thickness or the amount of sauce, but the subjective nuances that contribute to the taste – the perfect balance of flavors or the ideal texture – can only be captured through human feedback. RLHF incorporates this feedback into the learning process, allowing the AI to learn these subtleties and improve over time.
As we delve deeper into the transformative potential of generative AI, it’s imperative to keep the dialogue open, iterating and improving through constant human feedback. RLHF represents a pioneering step in this direction, ensuring our AI creations remain aligned with human values, preferences, and societal norms. The journey of AI development is a shared one, a testament to human ingenuity and our pursuit of a better future.
7. Mirror or Map?: Foundation Models or World Models#
The advent of Large Language Models (LLMs), such as GPT-4, has been a significant milestone in AI, leading to a key question: Do these models simply mirror their training data, or do they create a map of the world to generate their responses?
LLMs, though trained using a straightforward process of predicting the next word in a sequence, are exhibiting increasingly advanced behaviors. For example, they can write basic code or solve logic puzzles. However, the mystery lies in how they achieve this. Are they just regurgitating memorized data, or are they learning underlying rules? In essence, are they creating a model of the world that helps them understand the processes that generate the sequences they’re trained on?
This brings us to a core debate in the field: Are LLMs simply mastering the surface statistics (mere correlations) of language, or are they forming a causal model of how language is generated? This distinction is critical as it affects our ability to align the model with human values and mitigate spurious correlations.
A thought experiment can help illustrate this: Imagine a crow mimicking legal moves in a board game like Othello without seeing the board. You might initially think it’s just echoing common moves, but upon closer observation, you find that the crow is using birdseeds to mimic the game’s configuration. Upon manipulating these seeds, you notice the crow adjusts its calls accordingly, suggesting it has developed an understandable and controllable representation of the game state.
This analogy can be applied to LLMs. They seem to create a human-understandable “world model” in addition to their internal neural network processes. This is evidenced by the consistency between the predictions made by these two processes, suggesting a shared mid-stage representation.
We can analyze this representation using techniques like probing and intervention, which can establish a link between the world representation and the model’s internal activations. This could open up several applications, including the creation of latent saliency maps.
However, numerous challenges lie ahead. For one, can we reverse-engineer the world model from the LLM rather than assuming we already understand it? We are still in the early stages of understanding the world models that LLMs might be forming. Additionally, figuring out how to control these models effectively, yet non-invasively, is an important area of future research.
Act 4: The Autonomous Odyssey#
12. Economic Ecosystems: Agent Model#
Navigating the complex world of AI systems, we encounter a variety of different models, each with its own unique strengths and applications. Among these, the Agent Model stands out for its dynamic, interactive nature and its wide-ranging potential in simulating economic ecosystems.
At its core, the Agent Model is based on the concept of ‘agents’ – autonomous entities that make decisions based on a set of rules, their environment, and their current state. Each agent is capable of perceiving its environment, reasoning, learning, and taking actions to achieve its objectives. These agents can be as simple as a thermostat adjusting the temperature based on its readings, or as complex as a stock trading algorithm making decisions based on market trends.
The origins of Agent Models can be traced back to the field of economics, where they were first used to simulate and study complex economic systems. These models were able to capture the interactions between different economic actors, such as consumers, producers, and regulators, and provide insights into how changes in one part of the system could ripple through and affect the entire economy.
Over time, the applications of Agent Models have expanded far beyond economics. Today, they are used in fields as diverse as robotics, where they guide the behavior of autonomous robots; in environmental science, where they simulate the impact of climate change on various species; and even in social sciences, where they model the spread of ideas and behaviors through a society.
The real power of Agent Models comes from their flexibility and scalability. By adjusting the rules that guide the agents, or by adding or removing agents, it’s possible to create a wide variety of different scenarios and observe their outcomes. This makes Agent Models a powerful tool for exploring ‘what if’ scenarios, testing hypotheses, and making predictions about the future.
In the context of AI, Agent Models are particularly important because they provide a framework for building autonomous systems that can interact with their environment and learn from it. This is a fundamental requirement for many advanced AI applications, including self-driving cars, personal assistants, and intelligent tutoring systems.
As we venture further into the landscape of AI, the Agent Model continues to evolve and expand, opening up new possibilities and challenges. It is a cornerstone of the autonomous odyssey, a journey towards creating AI systems that can understand and interact with the world in ways that were once thought to be the exclusive domain of humans. In the next sections, we will delve deeper into the world of AI agents, exploring the cutting-edge models that are pushing the boundaries of what AI can achieve.
13. Creators of the New World: Generative AI Agent#
As we continue to traverse the complex yet fascinating landscape of AI, we encounter a class of intelligent entities known as Generative AI Agents. These agents, powered by the marvels of machine learning and artificial intelligence, stand at the forefront of the new world, weaving the fabric of our digital future.
A Generative AI Agent, unlike its reactive counterparts, doesn’t merely respond to stimuli in its environment. Instead, it takes a creative leap, generating new, original outputs from a learned understanding of its input data. These agents can create anything from pieces of art, music, and literature, to complex strategies for games and simulations, to entirely novel and unseen solutions for intricate problems.
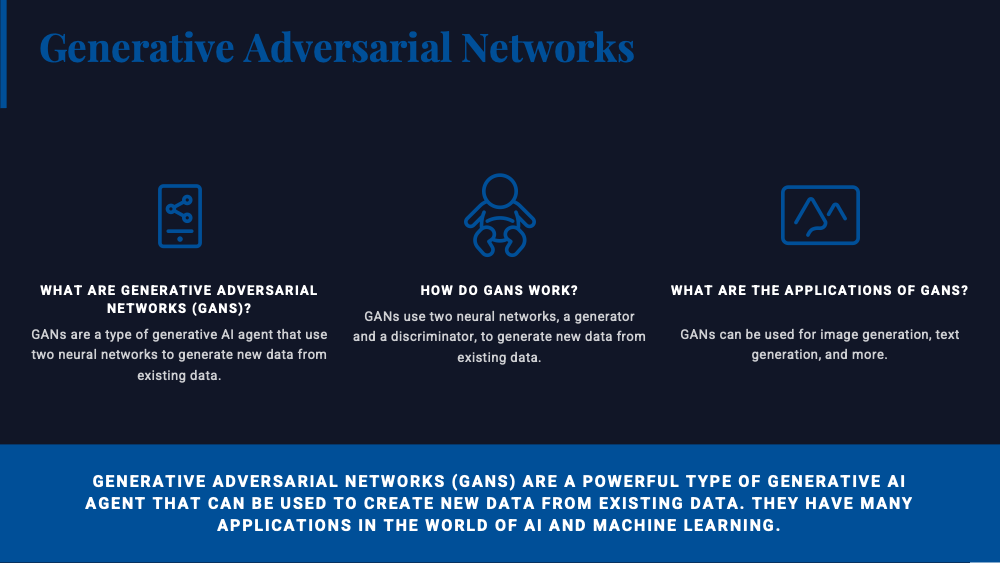
The underlying magic behind Generative AI Agents is a blend of advanced machine learning techniques, most notably, Generative Adversarial Networks (GANs). GANs consist of two parts: a generator that creates new data instances, and a discriminator that evaluates them for authenticity. They engage in a competitive dance, with the generator striving to create data that the discriminator can’t distinguish from real data, and the discriminator constantly honing its ability to spot fakes. This adversarial process leads to the generation of incredibly realistic and novel outputs.
But the impact of Generative AI Agents stretches beyond the realm of creating fascinating outputs. These agents, by virtue of their generative capabilities, have profound implications for a vast array of sectors. In the field of healthcare, they can be used to generate synthetic data for research, create personalized treatment plans, or even design new drugs. In the realm of entertainment, they can write scripts, compose music, or create stunning visual effects. In the domain of technology, they can devise novel algorithms, design intricate circuitry, or even innovate new technologies.
The journey of these Generative AI Agents is far from over. In fact, it is just beginning. As we continue to refine and expand their capabilities, they will undoubtedly play an increasingly significant role in shaping our world. They are the creators of the new world, carving out a future defined by the limitless possibilities of AI. As we move ahead in our narrative, we will delve deeper into specific examples of these agents, examining their inner workings and understanding their profound impact.
14. The Taskmaster: BabyAGI#
As our odyssey through the fascinating realm of AI continues, we now turn our attention to a new breed of AI systems, embodied by a system known as BabyAGI. This revolutionary AI-driven task management system is taking the world by storm, transforming the way we manage tasks and achieve our goals.
The brainchild of Yohei Nakajima, a venture capitalist, coder, and relentless experimenter, BabyAGI is envisioned as an autonomous AI agent designed to manage tasks with remarkable efficiency. Nakajima initially designed BabyAGI to automate various tasks he routinely performed as a VC—such as researching new technologies and companies. However, he soon realized the potential of his creation to benefit a broader audience. Stripping down the agent to its bare essentials, a mere 105 lines of code, he generously shared it on GitHub, opening up a world of possibilities for others to develop and customize their own specialized agents.
Operating in an unending loop, BabyAGI pulls tasks from a list, executes them, enhances the outcomes, and generates new tasks based on the objective and the outcome of the previous task. This perpetual cycle of task execution, result enrichment, task creation, and task prioritization allows BabyAGI to manage tasks in a way that is both effective and efficient. All of this is accomplished by harnessing the power of OpenAI and advanced vector databases like Chroma and Weaviate.
The versatility of BabyAGI is demonstrated in the multitude of app ideas designed to cater to a diverse range of needs and aspirations. For instance, imagine an app that uses BabyAGI to transform your goal of writing a sci-fi novel into an enthralling creative journey. All you need to do is input your initial task, such as brainstorming story themes, and let the app generate a list of inventive themes, characters, and plotlines, expertly prioritizing tasks to guide you through the writing process.
Likewise, BabyAGI can be employed to turn your aspirations of organizing a successful charity event into reality. Begin with the initial task of identifying potential event themes, and watch as the app conjures a list of imaginative themes, venue ideas, and sponsorship opportunities, prioritizing tasks for effortless event planning.
The secret behind BabyAGI’s power lies in its integration with GPT-4 and other AI models. It leverages GPT-4 to generate natural language texts for communication and task planning, while utilizing other models to perform various tasks such as web scraping, data analysis, and image processing. The versatility of BabyAGI paves the way for countless app development opportunities, catering to a broad spectrum of industries and interests.
From the Task Management Maestro, an app that helps individuals manage daily tasks and achieve goals, to the Project Management Virtuoso, an app designed to help teams manage their projects with heightened efficiency, BabyAGI’s potential applications are vast. It can even power apps like the Content Creation Connoisseur, which helps users generate inventive content for blogs and social media, and the Event Planning Master, which aids in planning and organizing events.
Beyond these specific applications, BabyAGI can also serve as a Personal Development Guru, guiding individuals on their journey of personal growth. Whether it’s acquiring a new skill or elevating fitness levels, BabyAGI is there to generate imaginative activities and habits, track progress, and adapt recommendations to match evolving needs.
In essence, BabyAGI is not just a task manager, but a guiding light, always nudging you towards success. It is a testament to the power and potential of AI, and a glimpse into a future where AI is not just a tool, but a companion in our journey towards achieving our goals. The journey continues, and as we explore more AI models,
15. Master of Goals: Auto GPT#
Stepping into the realm of greater autonomy and advanced abilities, we encounter Auto-GPT. This development takes AI’s potential to an entirely new level by incorporating the capability to perform intricate, multi-step tasks. A departure from previous LLMs, Auto-GPT ingeniously generates its own prompts, looping them back into its system until the job is accomplished, effectively becoming the master of its own goals.
Imagine an AI that not only answers the questions posed to it but also constructs the questions itself, determines subsequent steps, and establishes the course of action, thereby forming a self-regulating loop. This is the essence of Auto-GPT. It breaks down larger tasks into manageable sub-tasks, and interestingly, creates independent Auto-GPT instances to work on them. The original instance then acts as a project manager, coordinating the various tasks and synthesizing the output into a cohesive whole.
Going beyond the realm of constructing sentences and prose, Auto-GPT wields the power to scour the internet for relevant information and incorporate its findings into its output. This feature, coupled with a memory superior to that of ChatGPT, endows Auto-GPT with the ability to create and recall extended chains of commands.
Conceived by Toran Bruce Richards and powered by GPT-4, Auto-GPT represents a class of applications known as recursive AI agents. These agents are known for their ability to create new prompts based on generated results, chaining these operations together to perform complex tasks.
Auto-GPT’s capabilities span across various domains. From developing software applications from the ground up to enhancing businesses’ net worth through intelligent recommendations, Auto-GPT is truly redefining the scope of AI. It can even conduct market research, perform a range of tasks that once required human effort, and intriguingly, is capable of self-improvement by creating, evaluating, reviewing, and testing updates to its own code.
The emergence of recursive AI agents like Auto-GPT marks a watershed moment in AI’s evolutionary journey. But while they promise more creative, sophisticated, diverse, and functional AI output, their advent doesn’t absolve the challenges tied to generative AI. The issues of variable output accuracy, potential intellectual property rights infringement, and the risk of spreading biased or harmful content persist. Even more, these agents, with their ability to generate and run multiple AI processes, could potentially magnify these concerns.
As we stand at the precipice of this exciting new frontier, ethical considerations also come to the fore. Eminent AI experts like philosopher Nick Bostrom speculate that the latest generation of AI chatbots, such as GPT-4, may even exhibit signs of sentience, posing potential moral and ethical dilemmas.
Despite these considerations, the benefits of recursive AI agents are undeniable. They promise reduced costs and environmental impact associated with creating LLMs, as they find ways to make the process more efficient. As we continue on this journey, one thing is certain: AI will continue to evolve and reshape our world in ways we can only begin to imagine.
Act 5: A Glimpse into the Future#
16. Segmenting Reality: Segment Anything Model (SAM)#
As we journey forward into the realm of future possibilities, we encounter the Segment Anything Model (SAM), a revolutionary advancement in the field of image segmentation. Developed by Meta Research in April 2023, SAM is an instance segmentation model trained on a staggering 11 million images and 1.1 billion segmentation masks.
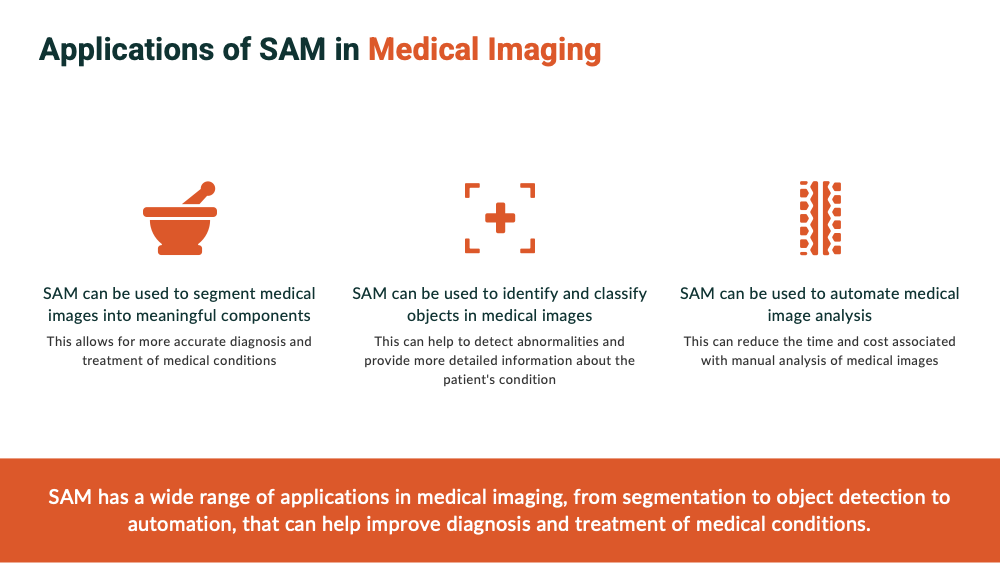
Segmentation is a process where digital images are partitioned into multiple segments or sets of pixels. Each pixel in a segment corresponds to a specific object, helping to create a clear distinction between different objects within an image. This process is crucial in fields such as medical imaging, where precise identification and isolation of objects are paramount.
Developing a segmentation model, however, is a formidable task. It requires not only robust infrastructure due to the computationally heavy nature of the models but also a well-curated dataset with corresponding masks for supervised learning. This becomes particularly challenging in specialized fields where obtaining high-quality datasets is both difficult and expensive.
Traditional segmentation models can broadly be divided into two types: interactive segmentation models, which require human intervention to generate the mask, and automated segmentation models, which rely on a large volume of manually annotated examples. Yet, neither of these approaches offers a fully automated, general-purpose solution, as they are either interactive or specifically trained on certain categories and instances.
Here is where SAM, the Segment Anything Model, steps in and changes the game. It is designed to be a foundation model for segmentation, offering both fully automated and interactive capabilities.
Drawing inspiration from natural language processing (NLP), which has been significantly advanced by foundation models, SAM aims to bring the same level of generalizability to image segmentation. NLP has benefitted tremendously from models trained on vast amounts of data, enabling zero-shot and few-shot learning. The same principles of the scaling law, including an increase in the number of parameters, data volume, and training duration, were applied to SAM, albeit with the added complexity associated with computer vision models.
SAM is not trained to segment specific objects. Instead, it learns a general concept of an object to be segmented, similar to how large language models learn a general notion of language. Once this foundation has been established, SAM can be adapted to segment images in various specific domains, such as cell images or underwater photos, without the need for additional training.
What sets SAM apart is its ability to respond to a variety of prompts including a set of foreground/background points, a rough box or mask, or free-form text, and produce a valid segmentation mask. Despite the potential ambiguity of these prompts, SAM is designed to generate at least one mask corresponding to one of the objects referred to in the prompt.
SAM’s ability to generate multiple valid masks from a single ambiguous point prompt demonstrates its potential for task generalization. Moreover, SAM is not limited to segmenting images into objects. It can also perform edge detection, super pixelization, and foreground segmentation, among other tasks.
The ultimate goal of SAM is to create a flexible, adaptable model that can handle a wide array of existing and new segmentation tasks through prompt engineering. This form of task generalization makes SAM the first of its kind—a foundation model for image segmentation that can adapt to any task, not predetermined during training.
As we delve deeper into the realms of AI, models like SAM serve as a testament to the infinite possibilities that lie in the future of artificial intelligence. It’s not just about segmenting reality anymore; it’s about reshaping it, one pixel at a time.
17. Dino’s Vision: DINO v2#
Our journey through the realms of AI brings us to a new milestone that echoes the concept of “Everything Everywhere All at Once” – DINO v2. An acronym for DIstillation of knowledge with No labels and vIsion transformers 2, this model is an innovative creation by Facebook AI, representing an advancement over its predecessor, DINO.
In essence, DINO v2 is a computer vision model that is trained using self-supervised learning. It not only matches but, in many cases, surpasses the performance of current specialized systems across a range of tasks, despite not requiring any labeled data for training. This represents a shift in the paradigm of computer vision, transitioning from the traditional dependence on manually labeled data to a future where AI can learn autonomously from large unlabeled image datasets.
Like a diligent student learning from a wise teacher, DINO v2 is structured around a teacher-student framework. This “student” network learns from the “teacher” network without the aid of labeled data, instead leveraging the power of contrastive learning to differentiate between various instances and features in images.
The innovation doesn’t stop there. In a fascinating twist, as the student network learns, the teacher network also improves. This is achieved by averaging the parameters of multiple student models, allowing both networks to continuously improve their understanding and provide more accurate feature representations.
DINO v2 represents a significant step beyond its predecessor, excelling in three key areas:
Multi-modal learning: It’s capable of learning from a variety of data types, such as images and videos, integrating them to form a more comprehensive understanding of the visual world.
Enhanced efficiency: It requires fewer iterations to achieve superior performance, making it faster and more resource-efficient.
Improved downstream performance: DINO v2 performs exceptionally well in a variety of downstream tasks, including object detection, instance segmentation, and action recognition.
With its high-performance features, Meta says, “DINOv2 can be used as inputs for simple linear classifiers”. This versatility makes DINO v2 an adaptable tool for a wide array of computer vision tasks, ranging from image-level tasks (image classification, instance retrieval, video understanding) to pixel-level tasks (depth estimation, semantic segmentation).
The applications of DINO v2 span across numerous industries. For instance, it can contribute to rapid and precise analysis of medical images such as X-rays and MRIs, potentially aiding disease diagnosis and treatment. Its prowess in deciphering complex visual data makes it a valuable asset for autonomous vehicles where real-time decision-making is vital. Moreover, DINO v2 can be employed in video analysis tasks, such as security monitoring and video editing, offering heightened accuracy and efficiency.
DINO v2’s emergence signifies a momentous milestone in AI’s journey towards understanding everything, everywhere, all at once. Its self-supervised learning capabilities offer a glimpse of the future where AI can learn and evolve autonomously, heralding an era of infinite possibilities for technological advancement and application.
18. The Binding Gaze: ImageBind#
As we journey further into the AI landscape, we encounter ImageBind, a revolutionary invention by Meta Research, launched in May 2023. It is an embedding model that brings together data from six different realms, or modalities - images and video, text, audio, thermal imaging, depth, and Inertial Measurement Units (IMUs) housing accelerometers and orientation monitors.
With ImageBind, you can input data in one modality - let’s say audio - and it’ll guide you to related content in a completely different modality - such as video. This multi-modal synergy is the crux of ImageBind’s potential.
In contrast to preceding models that incorporate data from one or two modalities into an embedding space, ImageBind integrates data from a multitude of modalities into the same space, enriching the resulting embeddings. This achievement is a substantial stride forward in the computer vision landscape, following the innovative trajectory set by Meta Research’s other pioneering models like the Segment Anything Model and DINOv2.
To unravel the workings of ImageBind, we need to understand its training process. It was tutored using paired data, each pair associating image data, including videos, with another modality. This combined data was then employed to train a massive embedding model. Examples include image-audio pairings and image-thermal pairings. ImageBind successfully demonstrated that features for different modalities could be learned using the image data in their training.
One of ImageBind’s key revelations is that associating images with another modality and integrating the results in the same embedding space can create a multi-modal embedding model. This paves the way for the elimination of separate models to map different modalities together.
ImageBind’s versatility extends to its potential applications. It can power information retrieval systems that traverse modalities. For example, you can embed data in supported modalities, such as video, depth data, and audio, and then create a search system that embeds a query in any modality and fetches related documents. This could enable cross-modal search systems, like a search engine that takes a photo and returns all the related audio materials.
Moreover, ImageBind’s embeddings can be utilized for zero-shot classification and few-shot classification, with the model demonstrating notable gains in top-1 accuracy. Even when juxtaposed with other audio models, ImageBind showcased robust results.
Perhaps the most exhilarating application of ImageBind lies in its potential for generative AI and augmented object detectors. For instance, Meta Research successfully employed ImageBind embeddings to enable audio-to-image generation with DALLE-2. This experiment signifies the potential of ImageBind embeddings for generative AI, eradicating the need for intermediary models to convert input data for use with a text embedding model.
In a different experiment, audio embeddings calculated using ImageBind were integrated with Detic, an object detection model. The outcome was an object detection model that could take in audio data and return bounding boxes for detections pertinent to the audio prompt.
In summary, ImageBind stands as a significant leap forward in the world of AI, offering a comprehensive, multi-modal approach to data interpretation and manipulation. As we explore the potential of ImageBind, we inch closer to our goal of understanding everything, everywhere, all at once, thereby further expanding the infinite possibilities within the realm of AI.
Epilogue: What Lies Beyond#
19. Infinite Possibilities: Conclusions - future directions, ethical considerations, and societal impact#
As we conclude our odyssey through the cosmos of AI, we find ourselves standing at the precipice of infinite possibilities. The advancements of AI we’ve journeyed through, from Turing’s echo to the binding gaze of ImageBind, are just the beginning, the nascent steps towards a future teeming with potential and innovation.
The future directions of AI hold the promise of truly autonomous systems that can learn, adapt, and interact with the world in ways that were previously the realm of science fiction. The development of world models and AI agents, combined with advancements in reinforcement learning, attention mechanisms, and multi-modal data interpretation, all contribute towards this vision.
We foresee AI systems that can seamlessly navigate multiple modalities, interpreting text, audio, visual, thermal, and depth data with an almost human-like understanding. Imagine a world where AI can understand and generate content across these modalities, creating a truly immersive, interactive AI experience.
However, as we venture into this new frontier, we must also confront the ethical considerations that such advancements bring to the fore. The power of AI comes with an equal measure of responsibility. We must ensure that the AI systems we develop are fair, unbiased, and respectful of privacy.
The ability of AI to imitate and generate human-like text, to understand and interact with the world, also raises concerns about misuse. The potential for deepfakes, misinformation, and manipulation is real and must be addressed proactively. Regulations and guidelines must be established to prevent misuse, and robust detection systems should be developed to identify AI-generated content.
Moreover, as AI becomes more integrated into our lives, questions of job displacement and economic disruption arise. It’s critical that we prepare for this, developing strategies for job retraining and economic support for those impacted. AI should be a tool for societal progress, not a source of division or inequality.
Finally, the societal impact of AI is immense and far-reaching. AI has the potential to revolutionize sectors from healthcare to education, transportation to entertainment. The benefits are plentiful - improved diagnostics and personalized medicine, adaptive learning systems, efficient logistics, and highly engaging, personalized content, to name a few.
Yet, we must also be aware of potential negative impacts, such as increased screen time, privacy concerns, and the digital divide. As we develop AI, we must also focus on ensuring that these benefits are accessible to all, and that the negative impacts are minimized.
The journey towards understanding everything, everywhere, all at once continues, a journey filled with exciting discoveries, challenging questions, and boundless possibilities. As we stride into this future, we carry with us the lessons of the past, the tools of the present, and the hopes and aspirations for a future where AI truly becomes a force for good, a transformative power that benefits us all.
In this grand narrative of AI, we’ve traced its footsteps from the emergence of a new era to a glimpse into the future. The story continues to unfold, and we invite you to join us in this journey of exploration, discovery, and growth. The future is here, and it is brimming with infinite possibilities. Let’s embrace it, together.