Motion Capture and Motion Synthesis#






Motion capture and motion synthesis are fundamental techniques in creating lifelike animations and interactive virtual characters. Motion capture records the movements of real-world subjects, while motion synthesis generates new, realistic motions based on the captured data or other inputs. Together, these techniques enable the creation of compelling and immersive experiences in various industries, from entertainment to medical applications.
Introduction#
Motion capture and motion synthesis are two crucial techniques in the field of computer graphics, animation, and virtual reality, enabling the creation of realistic and interactive character animations. They play a vital role in various industries, including film, gaming, sports, and medical applications. This introduction will provide an overview of motion capture and motion synthesis, explaining their importance and how they work together to bring digital characters to life.
Motion capture, often abbreviated as mocap, is the process of recording the movement of objects or people in real-time. This technique captures the position, orientation, and dynamics of a subject, typically using markers or sensors placed on key points of the body. These data points are then translated into a digital format, creating a 3D representation of the subject’s movements. Motion capture can be achieved through various methods, including marker-based, markerless, and inertial systems, each with their own advantages and limitations.
Motion synthesis, on the other hand, focuses on generating new, natural-looking movements for digital characters based on the captured data or other inputs. This process often involves blending and interpolating between different motion clips, creating smooth transitions and ensuring that the resulting motion appears seamless and realistic. Motion synthesis techniques can be categorized into two main approaches: kinematic and physics-based methods.
Kinematic motion synthesis models make predictions without necessarily satisfying physics constraints. These methods blend motion clips and concatenate them into a coherent trajectory, often using techniques such as motion graphs, motion fields, and recurrent neural networks. Parametric kinematic methods rely on time-series generative models, like variational autoencoders and autoregressive models, to maintain consistency in the predicted motion.
Physics-based motion synthesis, in contrast, generates motion predictions that adhere to the body dynamics and are informed by physics constraints, such as contacts and forces. These methods aim to produce more realistic movements by incorporating techniques like contact-invariant optimization, model-based sampling planning, and model-free reinforcement learning.
Phase-Functioned Neural Networks for Character Control#
by Holden et al. [2017]
Human-like Character Animation System Uses AI to Navigate Terrains
The paper, ‘Phase-Functioned Neural Networks for Character Control’, presents a novel neural network architecture called Phase-Functioned Neural Network (PFNN), designed for real-time character control in virtual environments, such as video games and virtual reality systems. The main goal is to produce natural and fluid character motions by learning from a large dataset of locomotion, including walking, running, jumping, and climbing movements.
The PFNN works by generating the weights of a regression network at each frame as a function of the phase - a variable representing the timing of the motion cycle. Once generated, the network weights are used to perform a regression from the control parameters at that frame to the corresponding pose of the character. This approach prevents mixing data from different phases, instead constructing a regression function that evolves smoothly over time with respect to the phase.
The methodology involves training the PFNN on a large, high-dimensional dataset where environmental geometry and human motion data are coupled. The neural network is capable of learning from this data, and once trained, it can automatically generate appropriate and expressive locomotion for a character moving over rough terrain, jumping, and avoiding obstacles in both natural and urban environments.
The training data preparation process includes fitting motion capture data into a large database of artificial heightmaps extracted from video game environments. This allows the PFNN to learn from a diverse set of motion data and interactions with the environment.
The main contributions of the paper are:
A novel real-time motion synthesis framework called Phase-Functioned Neural Network (PFNN), capable of performing character control using a large set of motion data, including interactions with the environment.
A process to prepare training data for the PFNN by fitting locomotion data to geometry extracted from virtual environments.
Audio to Body Dynamics#
by Shlizerman et al. [2018]
The paper ‘Audio to Body Dynamics’ presents a method that takes an audio input of violin or piano playing and outputs a video of skeleton predictions, which are then used to animate an avatar. The key idea is to create an animation of an avatar that moves their hands similarly to how a pianist or violinist would do, just from the audio input. The goal is to explore whether natural and logical body dynamics can be predicted from music at all.
The researchers built a Long-Short-Term-Memory (LSTM) network trained on violin and piano recital videos available on the internet. The network learns the correlation between audio features and body skeleton landmarks. The predicted points are applied onto a rigged avatar to create the animation.
The method consists of two main steps:
Building an LSTM network that learns the correlation between audio features and body skeleton landmarks.
Automatically animating an avatar using the predicted landmarks, resulting in an avatar that moves according to the audio input.
The researchers collected videos for both piano and violin recitals, processing them by detecting upper body and fingers in each frame of each video. They used a total of 50 points per frame, where 21 points represent the fingers in each hand and 8 points for the upper body.
Two separate neural networks were trained for each set (violin and piano). The output skeletons show promising results, producing interesting body dynamics. The supplementary videos provided with the paper demonstrate the effectiveness of the method in generating natural-looking animations from audio input.
Everybody Dance Now#
by Chan et al. [2019]
AI Can Transform Anyone Into a Professional Dancer
Everybody Dance Now is a paper that presents a simple method for motion transfer, allowing the performance of a source subject (a person dancing) to be transferred to a target subject (an amateur) after just a few minutes of the target performing standard moves. This method focuses on per-frame image-to-image translation with spatio-temporal smoothing, utilizing pose detections as an intermediate representation between the source and target subjects to learn a mapping from pose images to the target subject’s appearance.
The main contributions of this paper are:
A learning-based pipeline for human motion transfer between videos, which does not require expensive 3D or motion capture data.
The high quality of the generated results, demonstrating complex motion transfer in realistic and detailed videos.
The process involves the following steps:
Obtaining pose detections for each frame of the target video, yielding a set of corresponding pairs (pose stick figure, target person image).
Learning an image-to-image translation model between pose stick figures and images of the target person in a supervised way.
Transferring motion from source to target by inputting the pose stick figures into the trained model, obtaining images of the target subject in the same pose as the source.
Encouraging temporal smoothness in the generated videos by conditioning the prediction at each frame on that of the previous time step.
Increasing facial realism in the results by including a specialized GAN (Generative Adversarial Network) trained to generate the target person’s face.
This method allows untrained amateurs to perform complex movements like dancing, martial arts kicks, or spinning like ballerinas by transferring the motion from a source subject to the target subject.
SFV: Reinforcement Learning of Physical Skills from Videos#
by Peng et al. [2018]
This Reinforcement Learning Algorithm Can Capture Motion and Recreate It
Researchers from the University of California, Berkeley have developed a reinforcement learning-based system that can automatically capture and mimic motions it observes in YouTube videos. This advancement in character animation leverages motion capture data, which has been a popular source of motion data for decades.
Data-driven methods have been a cornerstone of character animation for decades, with motion-capture being one of the most popular sources of motion data. Motion-capture data is a staple for kinematic methods and is widely used in physics-based character animation. However, acquiring mocap data can pose challenges, often requiring heavily instrumented environments and actors. As an alternative, monocular video provides a more abundant and flexible source of motion data, but extracting motion information from these videos remains challenging.
In this paper, the researchers propose a method for acquiring dynamic character controllers directly from monocular video, using a combination of pose estimation and deep reinforcement learning. Recent advances in deep learning techniques have produced breakthrough results for vision-based 3D pose estimation from monocular images. However, pose estimation alone is insufficient for producing high-fidelity and physically plausible motions, as errors and inconsistencies accumulate, leading to unnatural character behaviors.
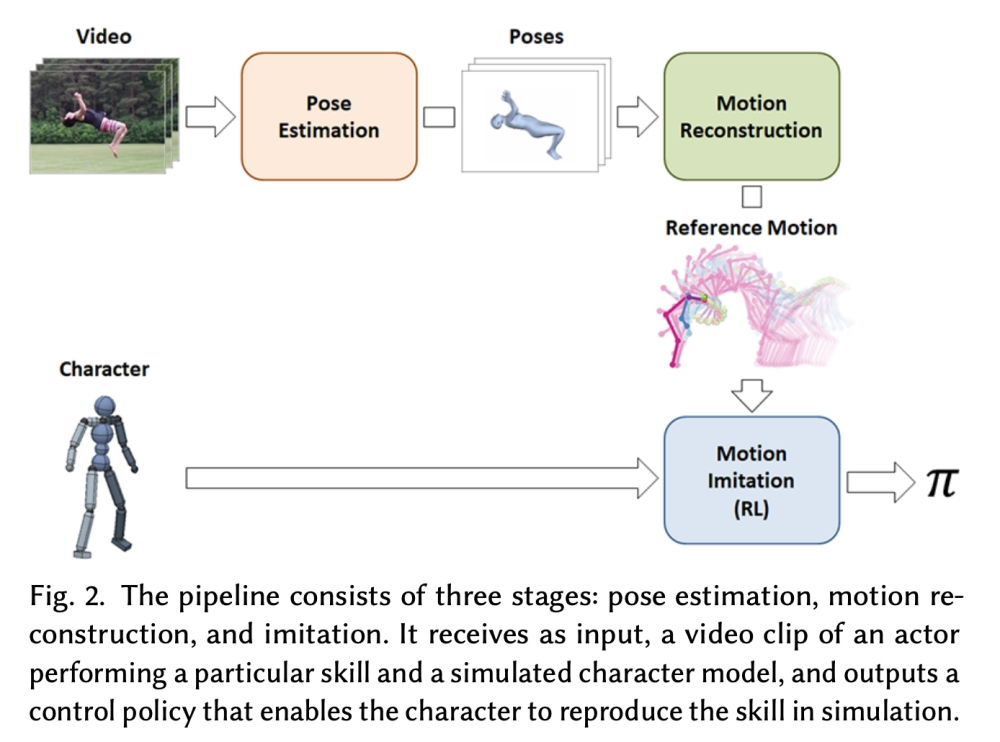
The proposed framework combines deep pose estimation and reinforcement learning to enable simulated characters to learn a diverse collection of dynamic and acrobatic skills directly from video demonstrations. The researchers introduce several extensions to both the pose tracking system and the reinforcement learning algorithm, including a motion reconstruction method that improves the quality of reference motions for imitation and an adaptive state initialization method for dynamic curriculum generation.
This framework can reproduce a significantly larger repertoire of skills and higher fidelity motions from videos than prior methods. It is evaluated on a large set of challenging skills, including dances, acrobatics, and martial arts, and can retarget video demonstrations to different morphologies and environments. Additionally, the researchers demonstrate a novel physics-based motion completion application that leverages a corpus of learned controllers to predict an actor’s full-body motion from a single still image.
DeepLabCut#
by Mathis et al. [2018]
DeepLabCut is an efficient method for 2D and 3D markerless pose estimation based on transfer learning with deep neural networks. It achieves excellent results, comparable to human labeling accuracy, with minimal training data (typically 50-200 frames). This versatile framework has been used to track various body parts in multiple species across a broad collection of behaviors. DeepLabCut is open-source, fast, robust, and can be used for computing 3D pose estimates or for multi-animal tracking. The package is collaboratively developed by the Mathis Group & Mathis Lab at EPFL.
Why use DeepLabCut?#
DeepLabCut has been successfully applied to various tasks and species, including trail tracking, reaching in mice, various Drosophila behaviors, rats, humans, fish species, bacteria, leeches, robots, cheetahs, mouse whiskers, and racehorses. The toolbox utilizes feature detectors from state-of-the-art algorithms for human pose estimation, such as DeeperCut. The package has evolved since then, adding faster and higher-performance variants with MobileNetV2s, EfficientNets, and DLCRNet backbones.
DeepLabCut offers several advantages, such as:
Little training data required: Transfer learning enables the network to learn from a limited number of training data for multiple, challenging behaviors.
Robustness to video compression: The feature detectors are robust against video compression artifacts.
3D pose estimation: DeepLabCut allows 3D pose estimation with a single network and camera, as well as with a single network trained on data from multiple cameras, combined with standard triangulation methods.

DeepLabCut is embedded in a larger open-source ecosystem, providing behavioral tracking for neuroscience, ecology, medical, and technical applications. Many new tools are being actively developed, such as DLC-Utils, which offers helper code.

DeepLabCut-Live!#
by Kane et al. [2020]
DeepLabCut-Live! is a new package that enables low-latency real-time pose estimation (within 15 ms, >100 FPS) using DeepLabCut. It features an additional forward-prediction module for zero-latency feedback and a dynamic-cropping mode for higher inference speeds. DeepLabCut-Live! offers three options for ease of use:
A stand-alone DLC-Live! GUI
Integration into Bonsai
Integration into AutoPilot
Additionally, performance has been benchmarked on a wide range of systems, allowing experimentalists to easily decide on the required hardware for their needs.
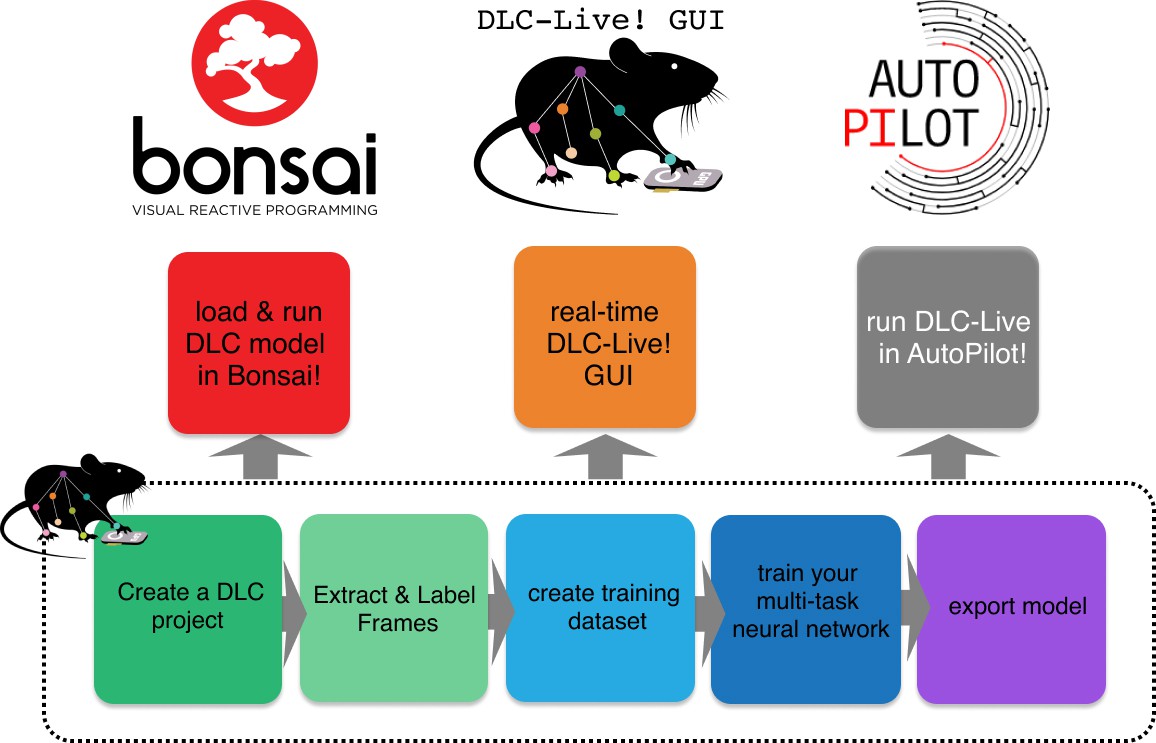
Figure 1: Overview of using DLC networks in real-time experiments within Bonsai, the DLC-Live! GUI, and AutoPilot.
DeepLabCut-Live! provides significant speed and latency improvements compared to existing real-time pose estimation software. The software optimizes inference code and uses lightweight DeepLabCut models, which perform well on GPUs, CPUs, and affordable embedded systems like the NVIDIA Jetson platform. A module to export and load trained neural network models easily has been introduced, improving model transfer between machines, model sharing, and integration with other software packages.
The package achieves low latency real-time pose estimation, with delays as low as 10 ms using GPUs and 30 ms using CPUs. The forward-prediction module can counteract delays by predicting the animal’s future pose, providing ultra-low latency feedback (even down to sub-zero ms delay). This level of performance has been previously attainable only with marked animals but not with markerless pose estimation.
DeepLabCut-Live! also includes a benchmarking suite to test performance on multiple hardware and software platforms. Performance metrics are available for ten different GPUs, two integrated systems, and five CPUs across various operating systems. The benchmarking suite is openly shared at DeepLabCut/DeepLabCut-live, allowing users to look up expected inference speeds and run the benchmark on their systems.
In summary, DeepLabCut-Live! is a powerful package that enables low-latency, real-time pose estimation using DeepLabCut. With its forward-prediction module, dynamic cropping mode, and integration options, it provides an excellent tool for experimental neuroscientists and researchers in various fields.
Physics-based Human Motion Estimation and Synthesis from Videos#
by Xie et al. [2021]
Generating Motion Capture Animation Without Hardware or Motion Data
The paper ‘Physics-based Human Motion Estimation and Synthesis from Videos’ proposes a framework for training generative models of physically plausible human motion directly from monocular RGB videos, eliminating the need for costly and time-consuming motion capture data. This approach opens up possibilities for large-scale, realistic, and diverse motion synthesis, with applications in graphics, gaming, and simulation environments for robotics.
The core of the method is a novel optimization formulation that corrects imperfect image-based pose estimations by enforcing physics constraints and reasoning about contacts in a differentiable way. This optimization yields corrected 3D poses and motions, as well as their corresponding contact forces.
The framework has two main contributions:
A smooth contact loss function is introduced to perform physics-based refinement of pose estimates, avoiding the need for separately trained contact detectors or nonlinear programming solvers.
The authors demonstrate that when visual pose estimation is combined with their physics-based optimization, it is sufficient to train motion synthesis models that approach the quality of motion capture prediction models, even without access to motion capture datasets.
The method is validated on the Human3.6m dataset, and the results show both qualitatively and quantitatively improved motion estimation, synthesis quality, and physical plausibility compared to prior work on learning-based motion prediction models, such as PhysCap, HMR, HMMR, and VIBE. By enabling learning of motion synthesis from video, this method paves the way for large-scale, realistic, and diverse motion synthesis.
MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model#
by Zhang et al. [2022]
The paper ‘MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model’ presents a novel framework for generating diverse and fine-grained human motions conditioned on natural language inputs, aiming to remove skill barriers for laymen in modern graphics applications.
The proposed method, MotionDiffuse, is the first diffusion model-based text-driven motion generation framework, offering several advantages over existing approaches:
Probabilistic Mapping: Instead of a deterministic language-motion mapping, MotionDiffuse generates motions through a series of denoising steps, injecting variations at each step to create diverse and realistic motion sequences.
Realistic Synthesis: MotionDiffuse excels at modeling complicated data distributions, generating vivid and natural-looking motion sequences that align with the input text.
Multi-Level Manipulation: The framework can respond to fine-grained instructions on individual body parts and supports arbitrary-length motion synthesis with time-varied text prompts, allowing for comprehensive motion generation and control.
The experiments conducted in the paper show that MotionDiffuse outperforms existing state-of-the-art (SoTA) methods in text-driven motion generation and action-conditioned motion generation. A qualitative analysis further highlights the framework’s controllability and ability to generate diverse and realistic human motions based on natural language inputs.
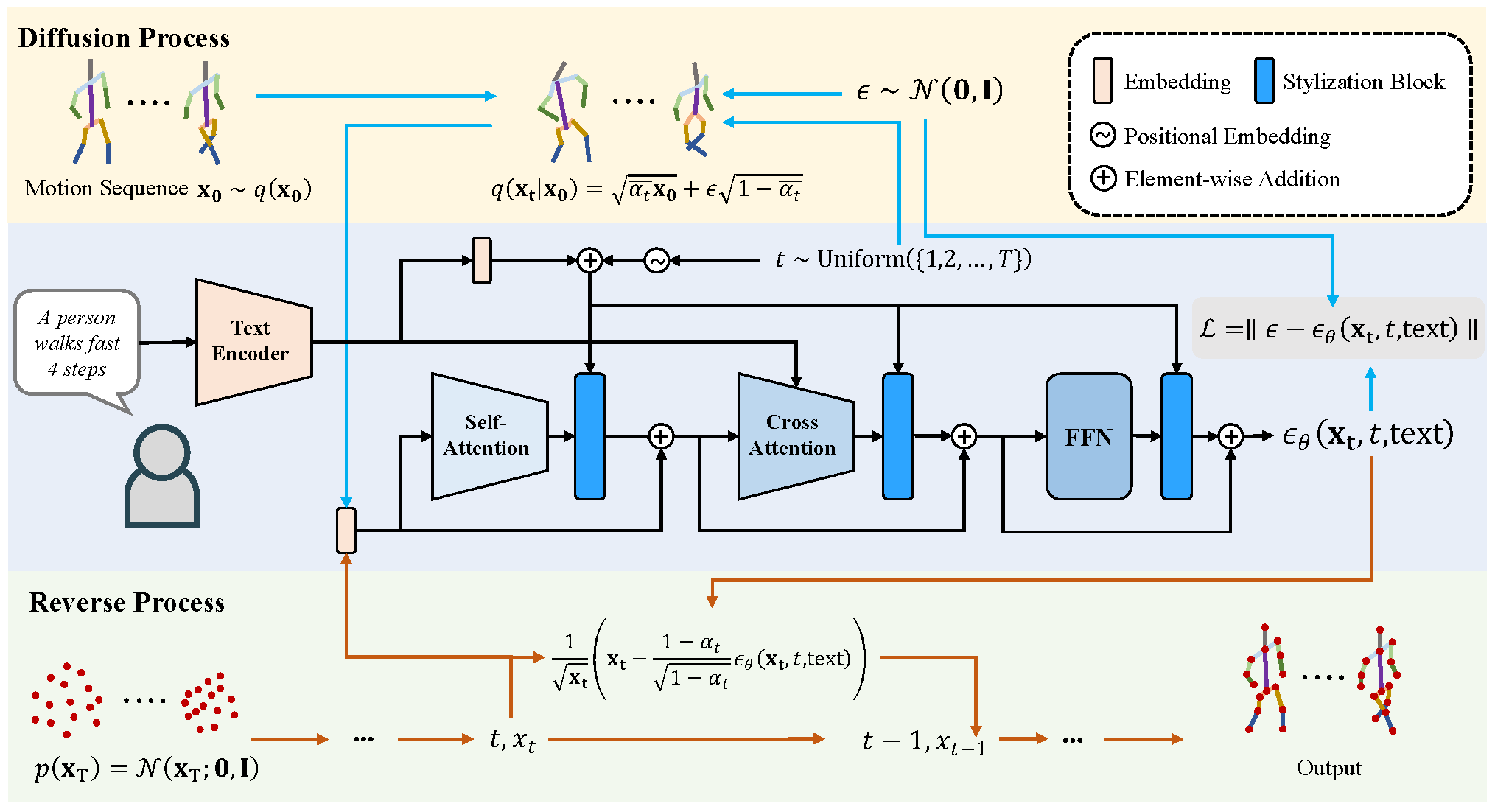
MDM: Human Motion Diffusion Model#
by Tevet et al. [2022]
The paper ‘MDM: Human Motion Diffusion Model’ presents a new generative model for creating natural and expressive human motion in computer animation. Generating high-quality and diverse human motion is a challenging task due to the complexity of motion, human perceptual sensitivity, and difficulties in accurately describing motion. Existing generative solutions often suffer from low quality or limited expressiveness.
The authors introduce Motion Diffusion Model (MDM), a classifier-free diffusion-based generative model for the human motion domain that is carefully adapted and transformer-based, combining insights from motion generation literature. MDM has several notable features:
Prediction of the sample: Unlike traditional diffusion models that predict noise in each diffusion step, MDM predicts the sample itself. This allows for the use of established geometric losses on the locations and velocities of the motion, such as the foot contact loss.
Generic approach: MDM enables different modes of conditioning and various generation tasks, making it highly versatile and adaptable.
Lightweight resources: The model can be trained with relatively low computational resources while still achieving state-of-the-art results on leading benchmarks for text-to-motion and action-to-motion tasks.
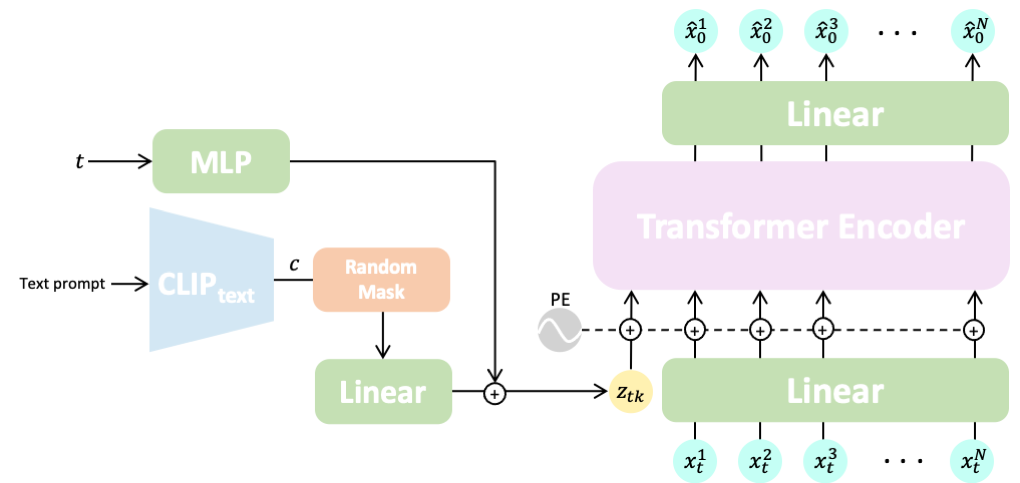
Generating Diverse and Natural 3D Human Motions from Text#
by Guo et al. [2022]
The paper ‘Generating Diverse and Natural 3D Human Motions from Text’ addresses the challenge of automatically generating 3D human motions based on textual descriptions. The goal is to create diverse and accurate motions that reflect the content of the input text. The authors propose a two-stage approach: text2length sampling and text2motion generation.
Text2length sampling: This stage involves sampling from the learned distribution function of motion lengths conditioned on the input text. It provides an appropriate length for the generated motion based on the textual description.
Text2motion generation: This stage uses a temporal variational autoencoder to synthesize a diverse set of human motions with the sampled lengths. The authors introduce a new internal motion representation called motion snippet code, which captures local semantic motion contexts and facilitates the generation of plausible motions that accurately reflect the input text.
To evaluate their approach, the authors create a large-scale dataset of scripted 3D human motions called HumanML3D. This dataset consists of 14,616 motion clips and 44,970 text descriptions, offering a rich resource for training and evaluating motion generation models.
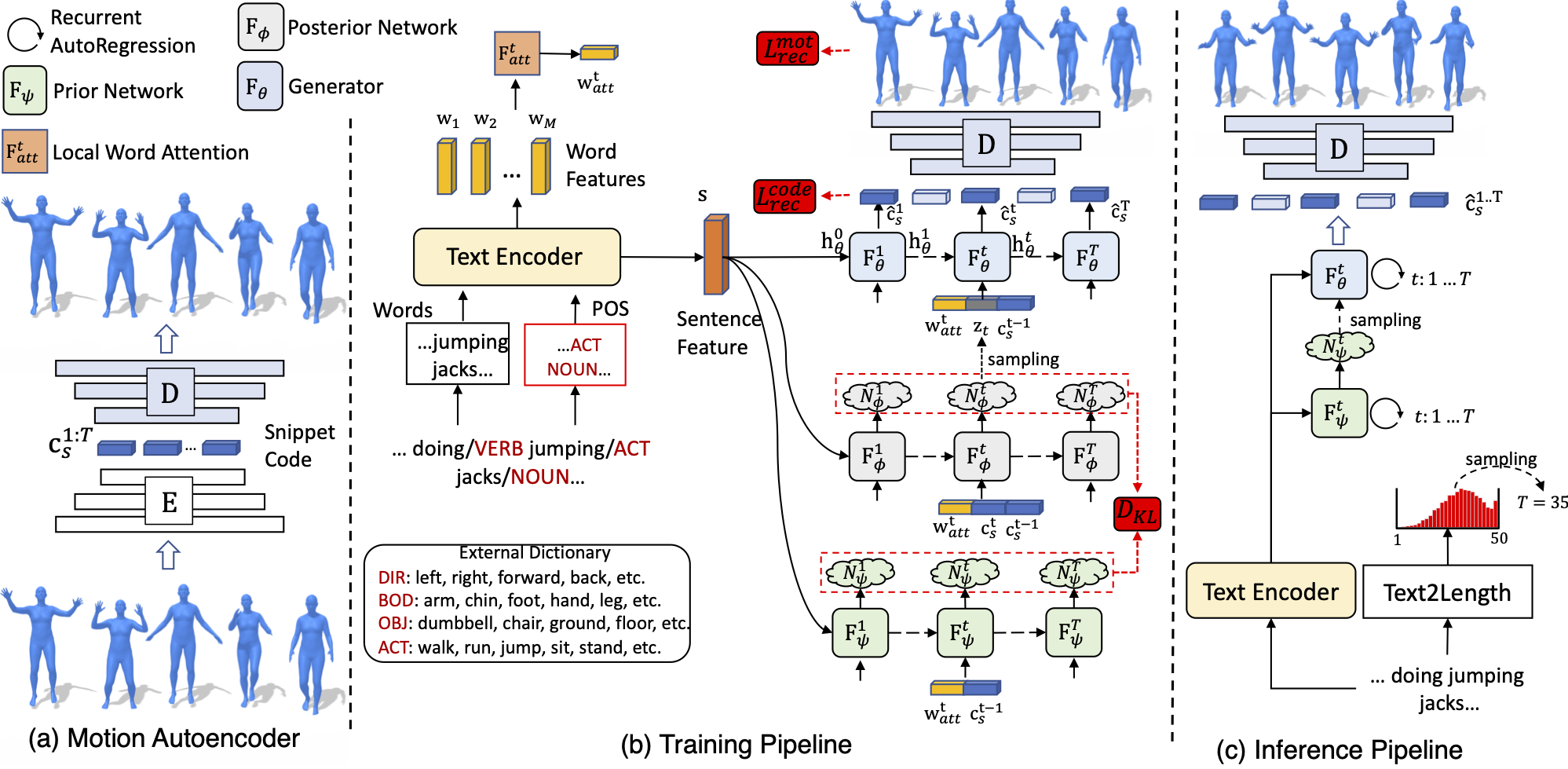
FLAME: Free-form Language-based Motion Synthesis & Editing#
by Kim et al. [2022]
The paper ‘FLAME: Free-form Language-based Motion Synthesis & Editing’ presents a novel approach for text-based motion generation, which is gaining increasing attention due to its potential in automating the motion-making process in industries such as gaming, animation, and robotics. The authors propose a diffusion-based motion synthesis and editing model called FLAME, inspired by the recent success of diffusion models in other domains.
FLAME integrates diffusion-based generative models into the motion domain, allowing it to generate high-fidelity motions that are well-aligned with the given text. Additionally, FLAME can edit parts of the motion, both frame-wise and joint-wise, without any fine-tuning, making it versatile and adaptable.
The authors introduce a new transformer-based architecture specifically designed to handle motion data. This architecture proves crucial in managing variable-length motions and effectively attending to free-form text.
FLAME is evaluated on three text-motion datasets: HumanML3D, BABEL, and KIT. The experiments demonstrate that FLAME achieves state-of-the-art generation performance on these datasets. Furthermore, the editing capability of FLAME can be extended to other tasks, such as motion prediction and motion in-betweening, which have previously been addressed by dedicated models.
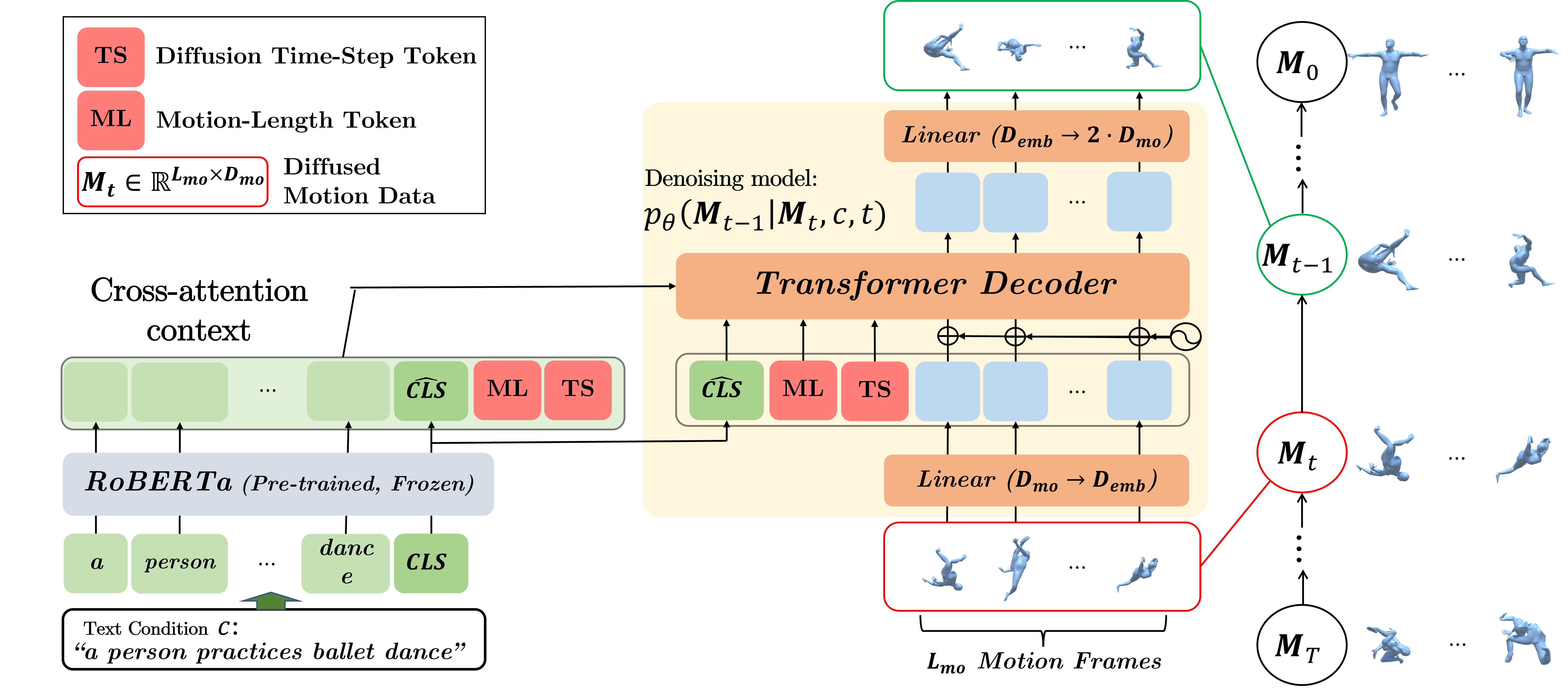
References#
Caroline Chan, Shiry Ginosar, Tinghui Zhou, and Alexei A Efros. Everybody dance now. In Proceedings of the IEEE/CVF international conference on computer vision, 5933–5942. 2019.
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5152–5161. 2022.
Daniel Holden, Taku Komura, and Jun Saito. Phase-functioned neural networks for character control. ACM Transactions on Graphics (TOG), 36(4):1–13, 2017.
Gary A Kane, Gonçalo Lopes, Jonny L Saunders, Alexander Mathis, and Mackenzie W Mathis. Real-time, low-latency closed-loop feedback using markerless posture tracking. Elife, 9:e61909, 2020.
Jihoon Kim, Jiseob Kim, and Sungjoon Choi. Flame: free-form language-based motion synthesis & editing. arXiv preprint arXiv:2209.00349, 2022.
Alexander Mathis, Pranav Mamidanna, Kevin M Cury, Taiga Abe, Venkatesh N Murthy, Mackenzie Weygandt Mathis, and Matthias Bethge. Deeplabcut: markerless pose estimation of user-defined body parts with deep learning. Nature neuroscience, 21(9):1281–1289, 2018.
Xue Bin Peng, Angjoo Kanazawa, Jitendra Malik, Pieter Abbeel, and Sergey Levine. Sfv: reinforcement learning of physical skills from videos. ACM Transactions On Graphics (TOG), 37(6):1–14, 2018.
Eli Shlizerman, Lucio Dery, Hayden Schoen, and Ira Kemelmacher-shlizerman. Audio to body dynamics. In Proceedings of the IEEE conference on computer vision and pattern recognition, 7574–7583. 2018.
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-or, and Amit H Bermano. Human motion diffusion model. arXiv preprint arXiv:2209.14916, 2022.
Kevin Xie, Tingwu Wang, Umar Iqbal, Yunrong Guo, Sanja Fidler, and Florian Shkurti. Physics-based human motion estimation and synthesis from videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 11532–11541. 2021.
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motiondiffuse: text-driven human motion generation with diffusion model. arXiv preprint arXiv:2208.15001, 2022.